自前でサイトのアクセス解析をする
本稿では、自分で運営するサイトのアクセス解析を「自前」で行う方法を紹介します。
アクセス解析とは
Google analyticsが有名ですが、サイトの来訪者の情報を収集して、サイトの質の向上、訪問者の増加、問い合わせや売上の増加を目的とするものです。
アクセス情報の収集には、いろいろな方法があります。
自サイトであれば、WEBサーバーのログを解析するのが一番確実な方法です。
オープンソースのアクセス解析ソフトウェアもあります。
今回紹介するのは、Googleなどが行っている、ページにJavascriptのプログラムを入れておき、その情報をサーバーのデータベースなどに保存する方法です。
analyticsを導入する際に、Googleさんが発行してくれたタグをHTMLに埋め込みますが、アレのことです。
当サイトで行っている方法
当サイトのページのソースを見ていただくと、次のようなものが</body>の直前に入っています。
<script type="text/javascript" src="/access/access.js"></script> <script type="text/javascript"> var _id = 1; _access(); </script>
ページが標示される際に、この部分が実行されます。
一番上で、アクセス解析情報を保存する処理の本体をファイルから読み込みます。
つついてJavascriptで、<em>idという変数を設定して、</em>accessという処理を呼び出しています。
_accessという処理は、最初のJavascriptのファイル中にあります。
_accessの処理では、Javascriptで集められる情報をまとめて、PHPのプログラムを呼び出します。
JavascriptからAjaxなどで直接PHPを呼び出さずに、PHPを呼び出すタグを生成して、それをHTMLに動的に埋め込んでいます。
サーバー上のPHPのプログラムは、渡された情報を、保存用のデータベースに書き込みます。
データベースの情報は、アクセス解析のページから確認ができます。
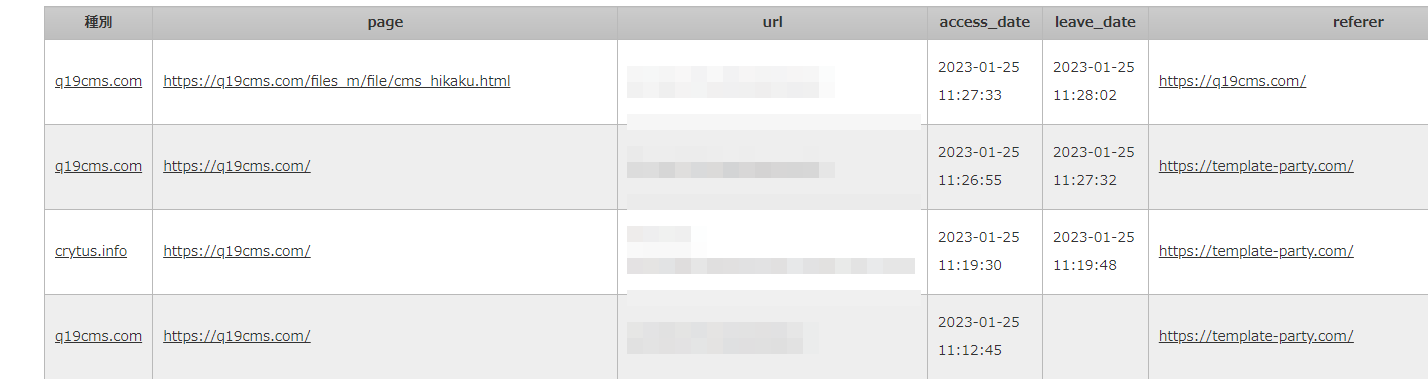
この画面では、収集した情報の一部を表示しています。
種別は、運営するいくつかのサイトのうち、どのサイトの情報かを表示しています。上記の_idの値で判定しています。
pageは、アクセスされたページのURLです。
urlは、アクセスをした人のURLもしくはIPアドレスを表示しています。
IPアドレスは確実にわかりますが、URLは設定されていないと取得できないので、その場合はIPアドレスの表示になります。
クローラーやボットには、URLにcrwlやbotの文字が含まれていることが多いので、それで判断できます。
access<em>dateはアクセスが有った日時、leave</em>dateは離脱した日時です。
離脱した日時は、ブラウザの機能を使っているので、ブラウザ以外からのアクセス(クローラー、ボットなど)や、ブラウザをいきなり閉じた場合は得られず、その場合は空欄になります。
refererは、参照元のページ(直前に表示していたページ)のURLです。
ここがgoogleだったり、yahoooの場合は、検索ページから来たことがわかります。
以前は、検索結果ページの完全なURLが入ってきたため、検索語句も得られたのですが、現在はその様な情報は含まれなくなりました。
これ以外には、アクセスしてきた、ブラウザのエージェント情報、当方のサーバーの情報なども保存しています。
この情報を使えば、analyticsが提供しているような、ページビューやユニークユーザ数などを求めることが可能になります。
analyticsとの一番の違いは、クローラーやボットのアクセスの情報がわかることだと思います。
※クローラーやボットは、プログラムにより、自動的にサイトを巡回して情報を収集するプログラムのことです。